 Home-theater-designers
Home-theater-designers
データ アナリストは、複数のデータセットを組み合わせる必要性に直面することがよくあります。分析を完了し、ビジネス/利害関係者のために結論を出すには、これを行う必要があります。
データが異なるテーブルに格納されている場合、そのデータを表現するのはしばしば困難です。このような状況では、作業しているプログラミング言語に関係なく、結合がその価値を証明します。
ddr4の後の数字はどういう意味ですか今日のメイク動画
Python の結合は SQL の結合に似ています。共通のインデックスで行を照合することによってデータ セットを結合します。
参照用に 2 つの DataFrame を作成する
このガイドの例に従うために、2 つのサンプル DataFrame を作成できます。次のコードを使用して、ID、名、姓を含む最初の DataFrame を作成します。
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)最初のステップとして、 パンダ 図書館。その後、変数を使用できます。 a 、DataFrame コンストラクターからの結果を格納します。必要な値を含む辞書をコンストラクターに渡します。
最後に、print 関数を使用して DataFrame 値の内容を表示し、すべてが期待どおりに見えることを確認します。
同様に、別の DataFrame を作成できます。 b ID と給与の値が含まれています。
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)コンソールまたは IDE で出力を確認できます。 DataFrames の内容を確認する必要があります。
Join は Python の Merge 関数とどう違うのですか?
pandas ライブラリは、DataFrame の操作に使用できるメイン ライブラリの 1 つです。 DataFrame には複数のデータ セットが含まれているため、それらを結合するために Python でさまざまな関数を使用できます。
Python は、DataFrame を結合するために使用できる他の多くの機能の中でも、結合およびマージ機能を提供します。これら 2 つの機能には大きな違いがあるため、どちらかを使用する前に覚えておく必要があります。
join 関数は、インデックス値に基づいて 2 つの DataFrame を結合します。の merge 関数は DataFrame を結合します インデックス値と列に基づいています。
Python の結合について知っておくべきことは何ですか?
使用可能な結合の種類について説明する前に、注意すべき重要な点をいくつか示します。
- SQL 結合は、最も基本的な機能の 1 つです。 Python の結合とよく似ています。
- DataFrame を結合するには、 pandas.DataFrame.join() 方法。
- デフォルトの結合は左結合を実行しますが、マージ関数は内部結合を実行します。
Python 結合のデフォルトの構文は次のとおりです。
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)最初の DataFrame で join メソッドを呼び出し、2 番目の DataFrame を最初のパラメーターとして渡します。 他の .残りの引数は次のとおりです。
- の上 複数ある場合、結合するインデックスを指定します。
- どうやって 、 どれの 内部、外部、左、右などの結合タイプを定義します。
- lsuffix 、 どれの 列名の左側のサフィックス文字列を定義します。
- 接尾辞 、 どれの 列名の正しいサフィックス文字列を定義します。
- 選別 、 どれの 結果の DataFrame をソートするかどうかを示すブール値です。
Python でさまざまな種類の結合を使用する方法を学ぶ
Python にはいくつかの結合オプションがあり、必要に応じて実行できます。結合の種類は次のとおりです。
1.左結合
左結合は、最初の DataFrame の値をそのまま維持しながら、2 番目のデータフレームから一致する値を取り込みます。たとえば、一致する値を b 、次のように定義できます。
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)クエリを実行すると、出力には次の列参照が含まれます。
- ID_左
- Fname
- 名前
- ID_right
- 給料
この結合は、最初の DataFrame から最初の 3 つの列を取得し、2 番目の DataFrame から最後の 2 つの列を取得します。それは、 lsuffix と 接尾辞 両方のデータセットの ID 列の名前を変更して、結果のフィールド名が一意になるようにします。
出力は次のとおりです。

2.右結合
右側の結合は、最初のテーブルから一致する値を取り込みながら、2 番目の DataFrame の値をそのまま保持します。たとえば、一致する値を a 、次のように定義できます。
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)出力は次のとおりです。
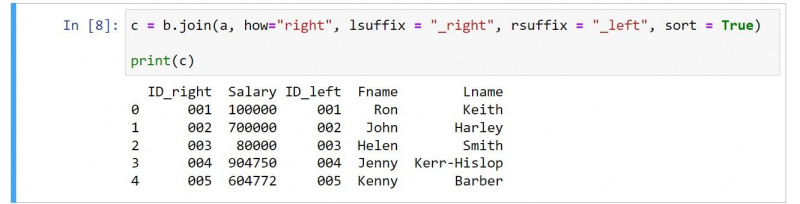
コードを確認すると、明らかな変更がいくつかあります。たとえば、結果には、最初の DataFrame の列の前に 2 番目の DataFrame の列が含まれます。
の値を使用する必要があります 右 のために どうやって 右結合を指定する引数。また、切り替える方法にも注意してください。 lsuffix と 接尾辞 右結合の性質を反映する値。
通常の結合では、右結合と比較して、左結合、内部結合、および外部結合をより頻繁に使用していることに気付く場合があります。ただし、使用法はデータ要件に完全に依存します。
3. 内部結合
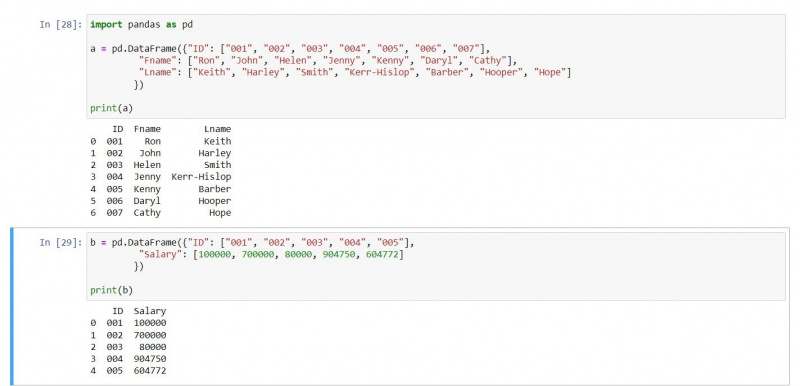
内部結合は、両方の DataFrame から一致するエントリを配信します。結合はインデックス番号を使用して行を照合するため、内部結合は一致する行のみを返します。この図では、次の 2 つの DataFrame を使用します。
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)出力は次のとおりです。
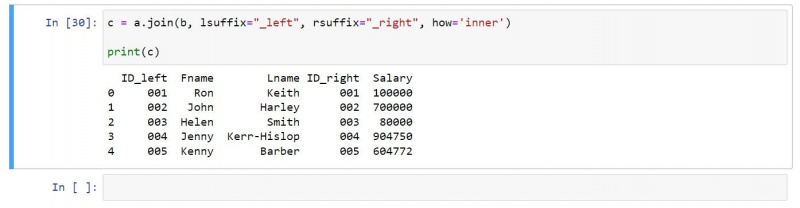
次のように、内部結合を使用できます。
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)結果の出力には、両方の入力 DataFrame に存在する行のみが含まれます。
4. 外部結合
外部結合は、両方の DataFrame からすべての値を返します。一致する値がない行の場合、個々のセルで null 値が生成されます。
上記と同じ DataFrame を使用して、外部結合のコードを次に示します。
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)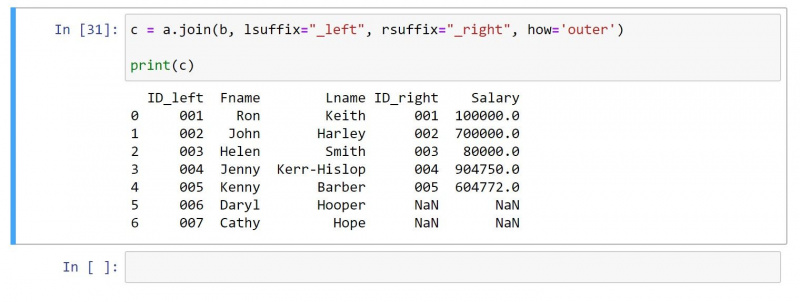
Python で結合を使用する
Join は、対応する関数である merge や concat と同様に、単純な結合機能以上のものを提供します。一連のオプションと機能から、ニーズに合ったオプションを選択できます。
Python が提供する柔軟なオプションを使用して、join 関数の有無にかかわらず、結果のデータセットを比較的簡単に並べ替えることができます。